|
March 30, 2007 The IMOs detection in video sequences acquired during driving is
challenging task, which is complicated by number of factors like egomotion,
shaking, imperfect calibration of the on-board cameras, variable
illumination conditions etc. All these factors cause
noise and decrease reliability of the visual cues estimations.
We propose an approach, which allows robustly detect IMOs
by processing and successive fusing two cooperative information
streams (see Fig. 1): independent motion detection stream
and objects recognition stream.
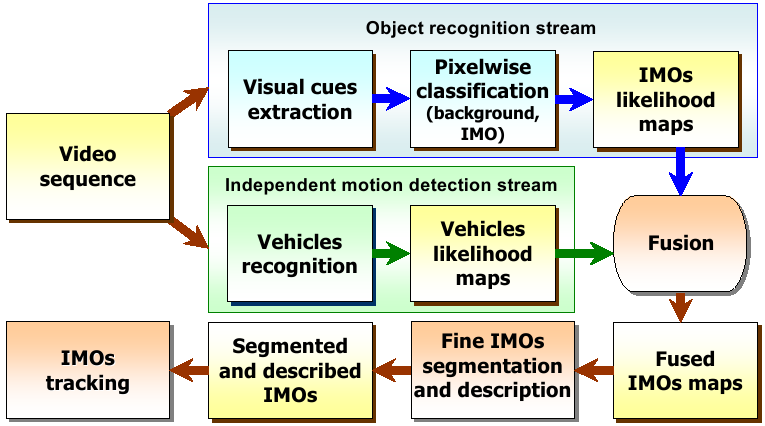
Fig. 1. Outline of the proposed model.
Using only motion stream for detection of IMOs leads to discontinuity and
sparseness of IMOs representations. Recognition stream deals with static
images and does not use the temporal information. It means that none these
streams alone can provide satisfactory quality of the final IMOs detection.
Besides, the idea of the two processing streams is widely accepted and
supported by visual neuroscience.
The problem of independent motion detection can be defined as the
problem of locating objects that move independently of the observer in his field
of view. In our case, we build so-called independent motion maps where
each pixel encodes likelihood of belonging to an IMO.
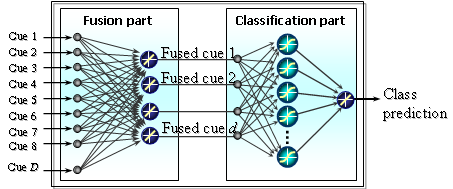
Fig. 2. MLP used as classifier in independent motion stream.
For each frame we build independent motion map in two steps: visual cues
extraction and classification. We consider each pixel as multidimensional vector
with visual cues as components. Using multilayered perceptron (see Fig. 2) we classify all the pixels (which have every component
properly defined) in two classes: IMO or background. After training, MLP can be
used for building a likelihood (of being IMO) map for entire frame.
 
Fig. 3. (Left) Frame number 342 of motorway3 sequence. (Right) Output of the
motion stream for the same frame. Intensity of each pixel means probability of
being part of the IMO.
For the recognition of vehicles and another potentially dangerous objects (such
as bicycles, motorcycles and pedestrians), we have used state of the art
recognition paradigm - convolutional network LeNet, proposed by LeCun and
colleagues1. Modifications of LeNet
were successfully exploited
for generic object recognition2 and even
for autonomous robot's obstacle avoidance system3 .
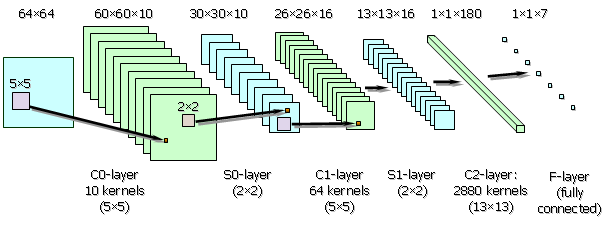
Fig. 4. LeNet - a feed-forward convolutional neural network, used in recognition
stream.
LeNet scans the input image (left frame) and builds likelihood maps
(see Fig. 5) for each class .

Fig. 5. Output of the recognition stream.
The two stream approach we presented is successful in IMOs detection and
classification, and allows for an easy tracking and properties retrieval
(Fig. 6). By mixing IMO maps and class
likelihood maps we increase the reliability of the detected IMOs and
automatically clean up the false positives. This is a crucial issue when video
streams obtained from moving cameras are used.

Fig. 6. Result of IMOs detection, tracking and description.
Further improvements of the model's performance we see in a combination of the
two processing streams at earlier stages. Namely, using a common bank of
Gabor-like (fixed/non-trainable) filters in the visual cues extraction stage and
in C0 layer of the LeNet. This step definitely will reduce computations. Another
way to reduce computations is to reduce the amount of data to process. In the
recognition stream, we can build the object likelihood maps not for the
entire frame, but only for regions containing motion information. The latter
has obvious biological support: in many biological visual systems, recognition
is preferable to moving objects. One more way to improve the model is by using
the CANBUS range radar data to refine the distance and speed up estimations.
References
[1]
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, "Gradient-based learning
applied to document recognition," Proceedings of the IEEE, vol. 86, no. 11, pp.
2278-2324, 1998.
[2]
Y. LeCun, F.J. Huang, and L. Bottou, "Learning methods for generic object
recognition
with invariance to pose and lighting," Proceedings of CVPR'04, vol. 2,
2004.
[3]
Y. LeCun, U. Muller, J. Ben, E. Cosatto, and B. Flepp, "Off-road obstacle
avoidance
through end-to-end learning," Advances in neural information processing
systems,
vol. 18, 2006.
Nick Chumerin
Karl Pauwels
Marc van Hulle
Laboratorium voor Neuro- en Psychofysiologie
Katholieke Universiteit Leuven
| 