|
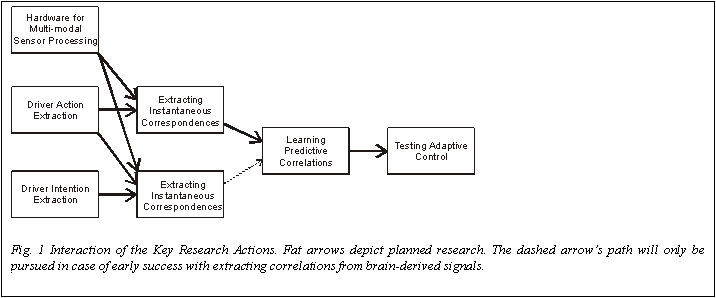
The Key Research Actions (KRAs)
1) Front-end Vision: Real time Adaptive Visual Sensors in Hardware 2) Perception
and Action extraction: Situation analysis extracting driving-relevant perceptual
events as well as relevant actions. 3) Driving School: Recognizing and learning
of the driving-relevant perception-action cycles. 4) Brain-derived signals:
Record and correlate eye-movements and EEG to driving sensor and motor events.
5) Warning and Action guidance by means of an Embedded Joint System: Transferring
the anticipatory control commands to car and driver and building a real-time
hybrid hardware/software system.
KRA1 Adaptive visual sensors in hardware
Action-extraction in the context of a car is a less complex problem; on
the other hand, the extraction of structured visual event in real time does
pose a major challenge. Hence, this KRA will focus on the first stage of the
image-to-information transformation process. In this context, information
on edges, disparity and motion play a key role. These features interact
to produce a more confident image-to-information transformation through a
joint-modality processing (Waxman and Duncan 1986, Sudhir et al. 1995, Farell
1998, Dornaika and Chung 2002, Gonçalves and Araújo 2003, Sabatini
et al. 2003). We will develop a hybrid hardware/software system that deals
with dense image structure extraction in real-time. The system will integrate
non-visual signals (such as steering angle, speed, etc) into the visual structure
processing scheme to efficiently and reliably extract robust features.
The goal of this KRA is to arrive at the so called multimodal (visual)
sensor. This system will process different visual modalities (multi-scale
optic flow, stereo, colour, etc) and combine them on the same platform by
cross-modal interactions between them as well as other non-visual sensor
information. The system parameters are adapted on-line through non-visual
modality information to obtain a predictive feature extraction. This process
reinforces the prediction obtained from visual modalities on the basis of
"good continuation" rules for 3D motion trajectories (Kanade et al. 1988,
Kuo et al. 2002, Piovoso and Laplante 2003).
In DRIVSCO, the different visual modalities will be processed in parallel
on a single device and merged to deliver the final output of our front-end.
Only due to the expertise with the current re-configurable technology and
their increased computational power we can address the implementation of such
a processing platform as a "System on a Chip" (SoC). Here we can also build
on the existing implementations of flow- and stereo-analysis designed in
the context of a previous project (ECOVISION)
(Díaz, et al. 2004, Díaz et al. 2005). This stage renders
multi-modal sensor analysis (with focus in vision) in real-time. Note that
such a system represents a highly desirable platform for a large variety
of applications in academia and industry, going beyond DRIVSCO. Furthermore,
the use of reconfigurable technology makes the system easy to adapt to different
application fields with specific requirements. We will also develop a specification
interface that allows a user to change the specifications of the system (optical
flow accuracy vs. efficiency, stereo & motion fusion rate for motion
in depth estimation, etc). After that, the concrete visual analysis model
will be compiled in silicon to run in real-time.
Outcome: This KRA provides the perceptual entities in real time for
the situation analysis in KRA2 of this project.
KRA2, Perception and Action extraction: Situation analysis extracting
driving-relevant perceptual events as well as relevant actions. To be
able to perform perception-action learning in KRA3 we need to first extract
a structured and low-dimensional visual event and action spaces.
Task 2.1 Action Space: The action space is quite restricted by nature
(Granlund 1999); for a car its degrees of freedom are the parameters of the
steering wheel, the forces on the brakes, gas pedal, the indicators, and a
few more. These actions will be chained into action sequences by means of
time-series analysis methods, to extract the most relevant and reoccurring
action components and to remove noise. This data will be binned along the
time axis to allow for a possible chaining of several sub-actions into an
action stream (or action chain). Action components like setting the turn-signal,
brakeing and turning will be specifically labelled, if detected again and
again. Such labelled sequences will also be set against their initial conditions
(e.g. initial speed) creating a labelled parameter dependent (mainly the speed
profile) data structure of structured action events (SAEs). This way, we
will achieve a sufficiently structured action space.
Task 2.2 Visual Event Space: To achieve a sufficient structuring
of the input space, we need to organise the low level descriptors such as
optic flow vectors or disparity estimates from KRA1 into a small number of
entities of higher meaning (in the following called structured visual events,
SVEs). To this end, the scene analysis pre-processed in KRA1 is turned into
the analysis and extraction of complete driving relevant perceptual situations.
This will be achieved in the following way: Early multi-modal visual features
(from the hardware, KRA1) can be bound to "Gestalt"-like entities using the
existing ECOVISION software (Wörgötter et al. 2004,
N. Krüger, M. Lappe and F. Wörgötter 2004). By analysing the
continuous stream of situations, repetitively occurring Gestalts will be
defined as candidates for an SVE. This process will also build in a "world-knowledge"
data base relevant to driving.
The mid-level vision part of this KRA2 will highly influence low-level
vision stages. One of the goals of KRA1 is to arrive at reliable multimodal
estimations. Top-down propagation of cues can be used to enhance the reliability
of low-level estimations. This way a recurrent process is implemented in
the DRIVSCO scene analysis software which will create something like a "signal-symbol"
loop that efficiently merges multimodal estimations into higher meaning entities
and also enhances the reliability of the low level estimations (signals) by
back-propagating cues extracted from higher level entities (symbols).
Task 2.3 Advanced data-mining in the SVE and SAE space: A car moving
forward creates a natural sequencing of SVE and SAE events. This sequence
can be seen as an analogy of a sentence while speaking also since the visual
events can be described verbally (Cavanagh, 2003) as well as the actions (braking,
steering, speeding…). Hence it is possible to use methods from text mining
and information theory (for review, Weiss et al., 2004) to improve the structuring
of the SVE and SAE space. SAEs occur mainly in a sequence, while SVEs can
to some degree also occur at the same time (several SVEs in the same camera
frame). This adds to the complexity of the problem in SVE-space. Hence the
following description focuses on SVEs; for SAEs some steps are easier. In
order to get a more robust representation of the spatially and temporally
varying SVEs, first frequency histograms of SVEs are formed (cf. word histograms
in document selection, Salton and McGill, 1983; Kaski et al., 1998; Proper
and Bruza, 1999; and feature histograms in object recognition, see Mel, 1997;
Schiele and Crowley, 2000). These frequencies are weighted by the confidences
of the SVEs ("correctness") and also by the presence of neighbouring (spatially
or temporally) similar SVEs (to support contextual information). In order
to avoid detecting erroneous or coincidental correlations between SVEs, we
develop an adaptive subspace transformation of SVEs in which the transformation
itself depends on the available action (SAE) labels (using the principle
of conditional mutual information; Principe et al., 2000; Torkkola, 2002).
The discriminative features that define the subspace then correspond to the
relevant SVE combinations. For the SAEs we determine the frequency histograms
of the binned action components (e.g., brakeing and turning), possibly weighted
with confidences (likelihood of occurrence when performing several trials)
and temporal context information (temporal windowing), to cluster the SAEs
directly (since the dimensionality and complexity is much lower than that
of the SVEs). The cluster prototypes then correspond to the SAE combinations
sought. For those action chains for which an action label is available, we
can again use the adaptive subspace transformation to reduce the chance of
detecting erroneous SAE combinations.
The outcome of KRA2 will be a stable and low-dimensional representation
of vision and action complexes, hence, of invariant visual events (SVEs) and
of relevant actions and action sequences of human drivers (SAEs) that are
used in KRA3 as input for the learning tasks. The low dimensionality of this
representation will guarantee real-time performance and will be essential
for the convergence of learning.
KRA3, Driving School: Recognizing and learning of the driving-relevant
perception-action cycles.
This KRA is concerned with three tasks:
Task 1) Recognition of "obvious" links between SVEs and driving actions:
Clearly there are some situations where SVEs will (or should) always lead
to a clear-cut and unambiguous reaction, like the above mentioned stopping
in front of a stop sign. These situations need not to be learned but can be
built into the system. Here we will analyse driving sequences step by step
and design a perception-reaction data base for such situations. Free parameters,
however, do exist in our example the speed of the car and the road condition,
which also need to be taken into account. This is where task 2 comes in for
the first time.
Task 2) Adaptive extraction of (non-obvious) links between SVEs and
driving actions: The pre-processing of the sensor and action space has
led to structured and fairly noise free SVE- and SAE-data. Hence we can assume
that SAEs will strictly follow SVEs in time. In this task we will develop
methods to pin down this association creating SVE-SAE pairs. To this end
the speed profile needs to be taken into account which stretches or compresses
the time axis for pairing. Also we need to disentangle complex situations.
Even at low speeds many simultaneous SVEs and SAEs can occur in complex situations
like in the inner city. Methods relying on statistical estimation techniques
will be used to disentangle this by analysing similar situations. To ease
the process, we will however start our tests in moderately complex scenes
first (country roads). Task one and two will build complete instantaneous
perception-action repertoires.
Task 3) Correlation based predictive learning of distant SVEs with actions
to be performed in the future: This is the core task of this KRA onto
which our application idea links. Two issues need to be addressed: 1) How
shall learning be achieved and quantified (algorithms, benchmarking). 2) How
shall learning and controlling be scheduled? Hence, when will the system know
that it can learn, and when will it have to stop learning, taking over control,
because the teacher (driver) actually performs ill himself/herself.
Task 3.1 Algorithm and Benchmarking: Algorithms: The main technique
which we will use relates to correlation based learning (Sun and Giles 2000).
Here DRIVSCO will make use of a powerful and simple conjecture. The forward
motion of a car creates a scenario in which the distant parts of the field
of (camera-) vision in a natural way represent the far future, while the proximal
parts represent the near future. As a consequence the distant field of vision
acts as a predictor of how the proximal field will look like a few split-seconds
later. Novel algorithms concerning sequence order learning exist in the hands
of the consortium (Porr and Wörgötter 2003, Porr et al 2003, for
a review see Wörgötter and Porr 2005), which can temporally correlate
the distant view to the later occurring actions of the driver (when the distant
view for him/her has become the action-relevant proximal view). These algorithms
are related to machine learning algorithms used in Actor-Critic architectures
in reinforcement learning (Barto 1995, Sutton and Barto 1998). Fig. 2 shows
a preliminary result where this principle has been successfully employed
in a simple robot setup. Note, this setup is without a driver, but can explain
the principles very well.
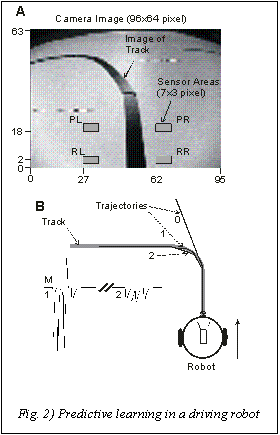
The goal was to learn a left curve by a driving robot equipped with a forward
pointing camera. Since here we do not have a "driver", we define, instead,
a reflexive reaction path from the sensor arrays RL and RR in the camera image
(Fig. 2A). Whenever the line crosses either RR or RL a counter-steering reaction
is elicited as if a driver reacts rather late to a road-lane crossing. Hence
in this example the reflex creates an instantaneous perception-action repertoire.
Sensor arrays PL, PR in pixel-lines more at the top correspond to the far
future of the robot's trajectory and act predictive in comparison to sensor
arrays RL, RR at the bottom. This correlation is being learned creating a
predictive perception-action repertoire. Three trials are shown in panel
B, between which connection weights were frozen and the robot was manually
returned to its starting position. Different from a driver, who would not
drift off the road, the reflex alone does not always succeed (Fig. 2B, Trajectory
0). However, the cumulative action of reflex and predictive response allows
the robot to stay on the line already during the first learning trial (Trajectory
1). In the second trial it can follow the line smoothly. In the first learning
trial (1) the motor signal M shows three leftward (down) and one rightward
(up) reflex reactions, in the second learning trial (2) only much smoother,
non-reflexive, leftward steering signals were obtained. This mechanism works
in a robust way also for more complex, left-right curved parcours. The algorithm
can also cope with a wide range of temporal delays between reflex and predictor
(e.g. when driving at different speeds). This simple example can be extended
to more complex perception-action-repertoires using the same learning principle.
Here the (built-in) reflex and the predictor of the system need to be replaced
by perception-action repertoires from task 2 with the proper temporal structure
(early versus late) and the number of different outputs will have to be augmented
to go beyond mere steering actions.
Benchmarking and Testing: In general we will perform learning on a far
more advanced robot setup first. Next we will test it off-line on image/action
sequences recorded in a test car. The robot setup will include a human driver,
hence it is a simplified driving simulator built to scale on a road-like parcours
also simulating low-beam and IR-night vision. This procedure will allow us
to also create more extreme situations for KRA4 as well as restricted scenes
for benchmarking and testing before going to the test cars of Hella. The
main reason why we do not want to use a conventional driving simulator is
that we hope to arrive at full, autonomous, learned control in the robot,
for which an embodied system is needed. Also learning may need of very extensive
databases of recorded driving sequences. Hence this scaled-down testing scenario
facilitates learning in a well-defined environment.
Task 3.2 Stable control and scheduling of learning: Stable control:
In the car the driver must remain in control (industrial safety requirements)
and only warning/haptic signals will be created. In the robot that simulates
driving, "taking over control from the driver" scenarios can be developed
and tested in the following way: Before learning the robot is also controlled
by its driver. This represents the stable ground state and stability is guaranteed
by the actions of the driver who is "part of the learning algorithm". After
learning the system performs anticipatory actions in response to earlier (hence
distal) information. Thus, the algorithm can now react earlier to looming
events (improved ground state). Ultimately it is in the same way possible
to try this in a test car on a specific parcours off the regular roads. Scheduling
of learning: Since our approach is designed to learn from the behaviour of
the driver, a major conceptual problem arises when the behaviour of the driver
is non-optimal in itself. We will investigate local and global variations
of the learning scheme to deal with this problem. On the local scale, which
corresponds to short time scales, we will incorporate smoothness constraints
on the system behaviour that punish abrupt changes in the driving which are
typical of erratic or dangerous driving styles. On a global scale, we will
in general assume that driving errors are few and of minimal consequence during
the day and the system shall be in "learning mode" then. It will learn to
associate distant events in an anticipatory way to driving actions as explained
above. During the night it will be able to apply the learned associations
to the field of infra-red night vision (beyond the visual field of the driver).
Using these two constraints learning can be scheduled in a reliable way.
Outcome: KRA3 provides the learning scheme for the predictive learning
of perception-action cycles based on perception-action-repertoires and the
learning of vision-action complexes. The simplicity of the employed learning
algorithm will make sure that the final system can operate still in real-time.
KRA 4: Brain-derived signals: Record and correlate eye-movements and
EEG to driving sensor and motor events.
A further objective of this research is to assess to what degree brain
derived signals can be used for control (of a car). Over the last years it
has become possible to coarsely control robot arms with neuronal activity
(Wessberg et al 2000, Isaacs et al 2000) as well as to interact with totally
locked-in ALS patients via their EEG (Birbaumer et al, 1999, Pfurtscheller
et al., 2003), or navigate in virtual environment (Bayliss, 2003, Friedmann
et al, 2004). All these techniques are at a very early stage but we believe
that it is now possible to address similar questions also in the context
of driving control (e.g. see experiments by Bayliss and Ballard, 2000). Ultimately
the goal of such research is to help disabled people to control machinery,
For the time being we will measure the signals and correlate them to SVEs
and SAEs, assessing the quality and robustness of these correlations. These
data are indispensable for attempting the second step, namely actual control.
Interestingly, eye-movement data as well as EEG data can be considered just
as other classes of structured action events (SAEs) and thereby embedded into
the framework described above.
The project parts described above will finally result in robust sets of
SVEs and SAEs, and the time points of their occurrence. These points of time
will constitute candidate time windows for the analysis of EEG signals and
eye-movements. Analysis of the correlation of either signal group and the
SVEs and SAEs, respectively, will be done using reverse-correlation techniques
(Ringach and Shapley 2004) with gradually widened time windows. Moreover,
for the analysis of the EEG signals, we will first use event-related averaging
methods in order to get a first impression of candidate wave-forms allowing
us to look for them in the raw, unaveraged EEG during later stages of the
project.
Task 4.1 Eye-movements: Here the situation is less problematic.
There is proof that eye-movements correlate with the state of attentiveness
of the driver and with the directedness of attention (Hayhoe & Ballard,
2005, Lappe & Hoffmann, 2000). Preliminary results have also been recorded
by UMU during different viewing tasks (see Fig. 8). Moreover, eye movements
can be used to predict the intended action of the driver on the car as they
typically precede goal-directed actions (Land, 1992; Land & Lee, 1994;
Land & Tatler, 2001). This allows eye-movement SAEs to be correlated with
driving-related SAEs. Therefore, we will measure eye-movements during driving
and define another SAE class through time-series analysis and binning, similar
to the actual driving SAEs above.
Task 4.2 EEG: EEG measurements have been used in a driving context
mainly with regard to the attentional state of the driver (Baulk, Reyner,
Horne, 2001; Bergamasco, Benna, Covavich & Gilli, 1976; Horne & Baulk,
2004;), but there were also attempts to recognise driving-specific objects
in virtual driving environment (Bayliss and Ballard, 2000). In order to measure
the EEG we will exclusively use the driving simulator, because in a car electrical
noise problems will make the recording more complicated. The rather fine signal
structures which might be correlated to SVEs and SAEs would certainly be
lost this way. We will proceed in two stages. (1) first we will simulate extreme
situations (e.g. a looming collision) hoping that this will lead to measurable
signals in the EEG, (2) while in the second stage we will analyse regular
driving situations in the same way. Starting with averaging methods and
using reverse correlation we should be able to detect signal structures correlated
to SVEs and to the conventional driving SAEs by the end of the project. The
complexity of this project part is such that only at the end of the project
we will be able to use the found correlations for the above described learning.
This will be done on the robot.
KRA 5: Warning and Action guidance by Means of an Embedded Joint System:
This is a technical KRA and will only be described briefly. This KRA will
combine the components of KRAs1-3 into a joint hardware-software system. This
is required in order to transfer actions and warning and haptic signals derived
from the predictive learning in KRA3 to the car and its driver. Bernstein
Center in Goettingen (BCG) and University of Granada (UGR) have expertise
in performing such integration. BCG has been involved in prototype development
from R&D projects in conjunction with his former company ITL Ltd. which
operates in this field at his former Scottish affiliation (Univ. of Stirling).
UGR has, together with Hella, already performed such an implementation in
the conjunction with ECOVISION's rear-view mirror warning system (Díaz
et al, 2005).

|

